Methodologies of Group Sequential and Adaptive Designs
September 29, 2025
rpact 📦
Comprehensive validated R package implementing methodology described in Wassmer and Brannath (2016)
Enables the design of traditional and confirmatory adaptive group sequential designs
Provides interim data analysis and simulation including early efficacy stopping and futility analyses
Enables sample-size reassessment with different strategies
Enables treatment arm selection in multi-stage multi-arm (MAMS) designs
Enables subset selection in population enrichment designs
Provides a comprehensive and reliable sample size calculator

Developed by RPACT 🏢
RPACT company founded in 2017 by Gernot Wassmer and Friedrich Pahlke
Idea: open source development with help of “crowd funding”
Currently supported by 21 companies
\(>\) 80 presentations and training courses since 2018, e.g., FDA in March 2022
29 vignettes based on Quarto and published on rpact.org/vignettes
28 releases on CRAN since 2018


![]()
Group Sequential Designs: Basic Theory
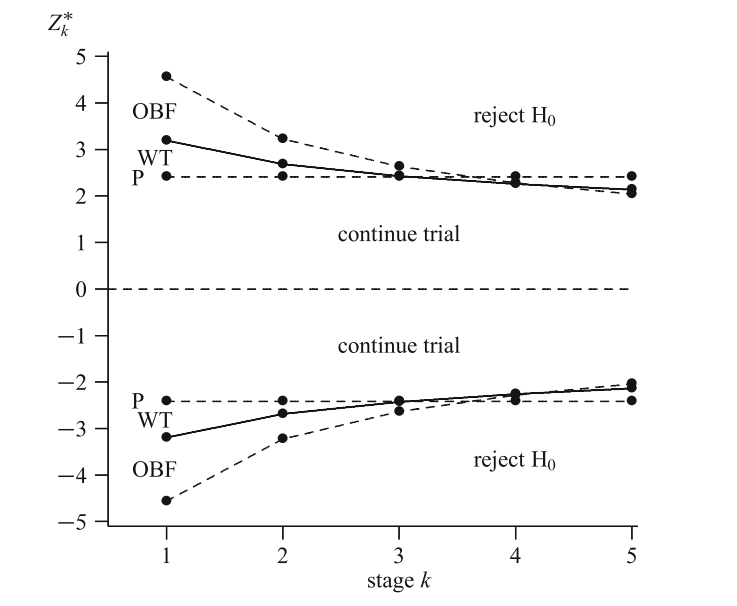
Wang and Tsiatis \(\Delta\)-class \(u_k = k^{\Delta-0.5}\). O’Brien and Fleming: \(\Delta\) = 0; Pocock: \(\Delta\) = 0.5
How this is done with rpact
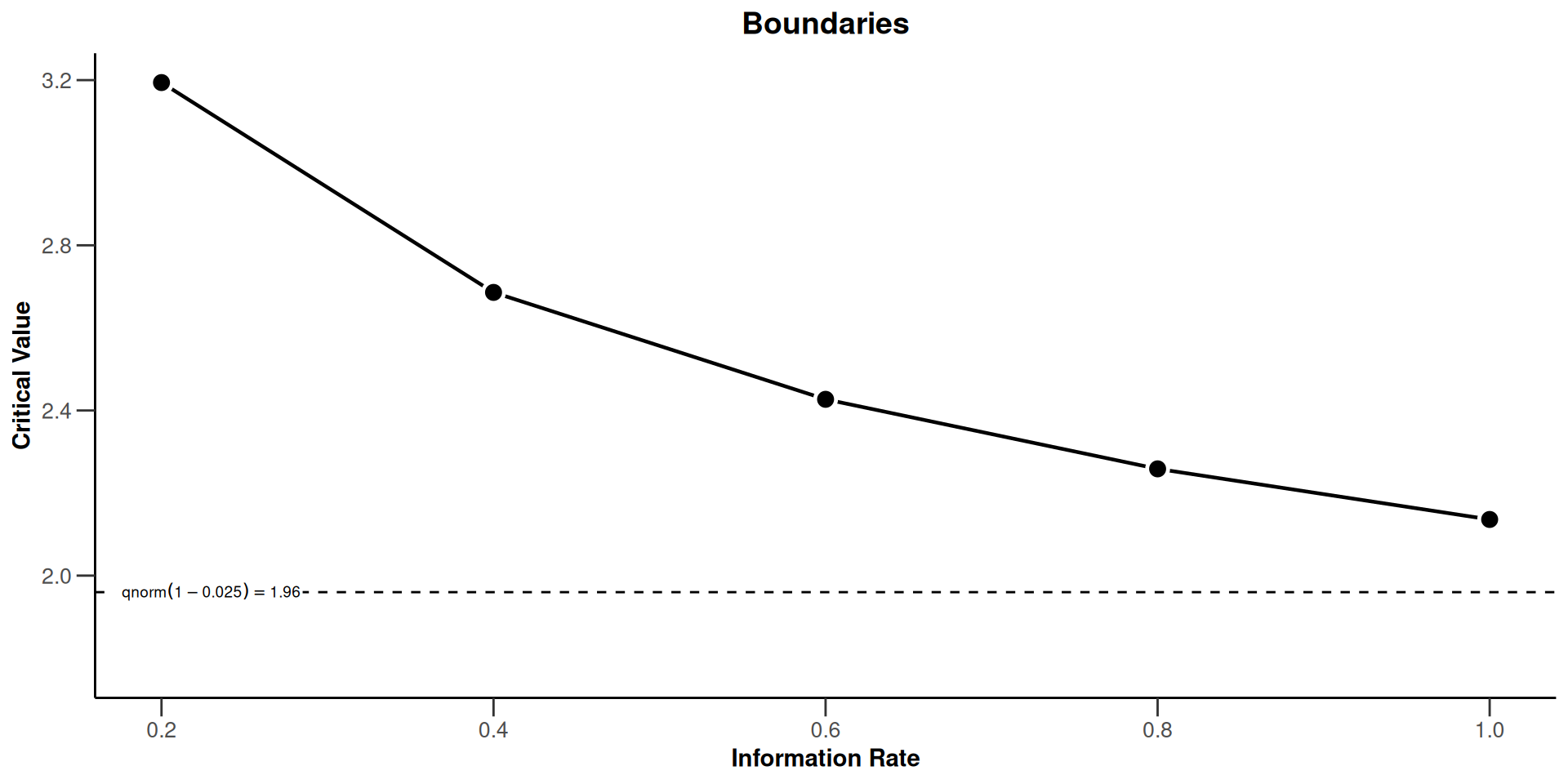
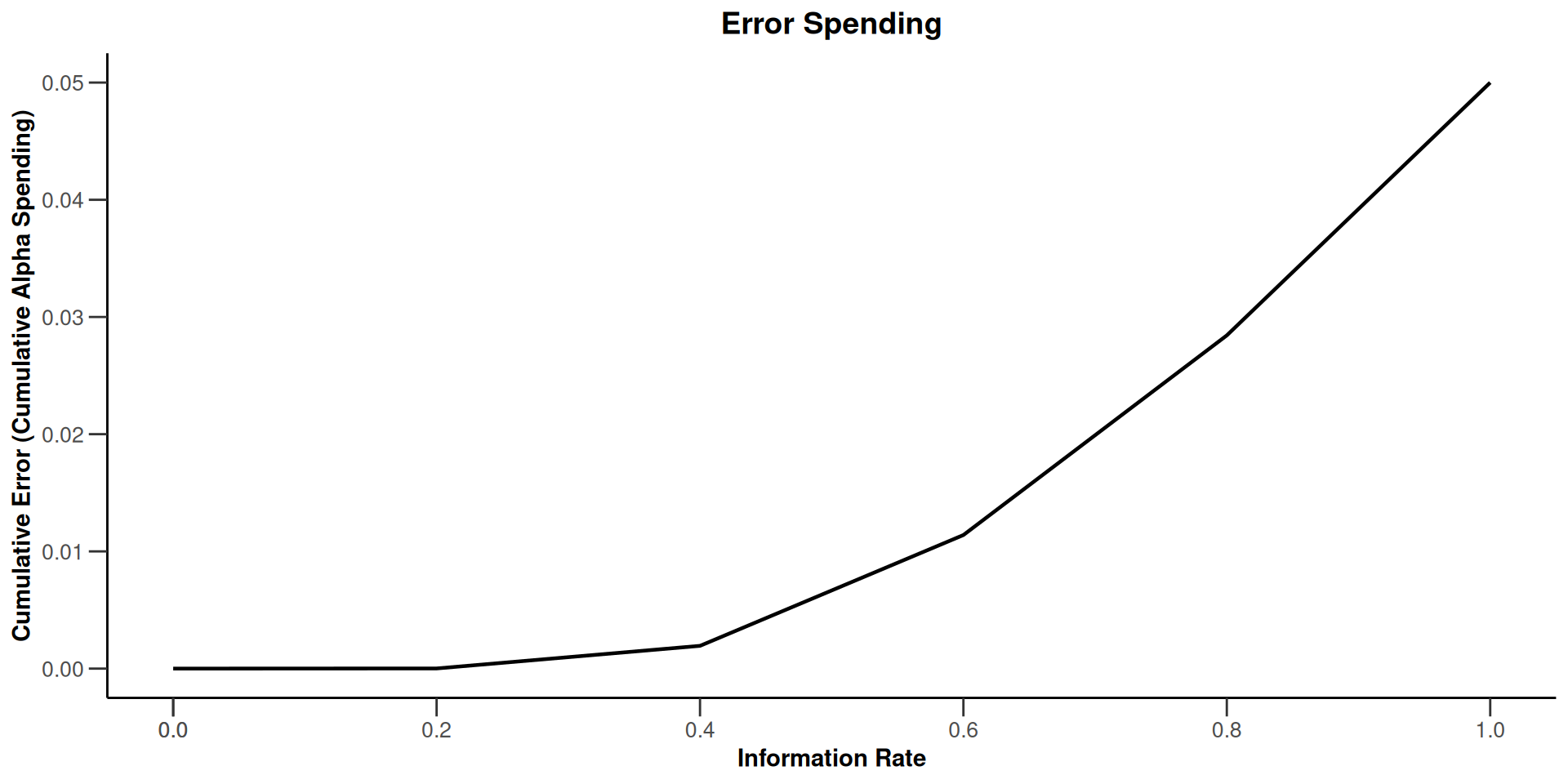
The Use Function Approach
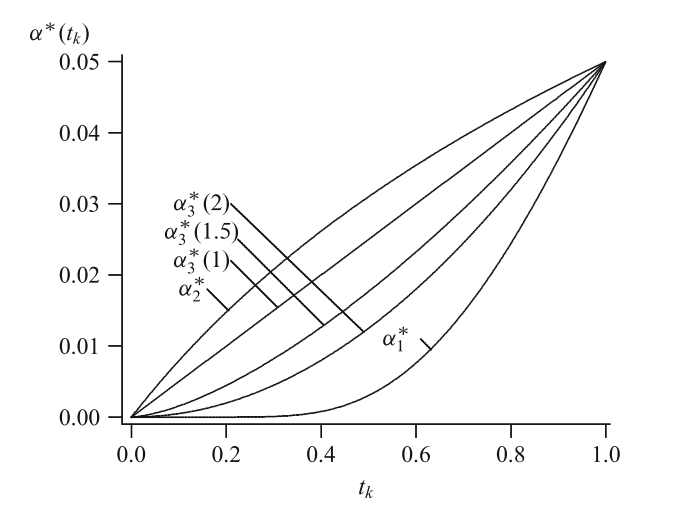
Examples of \(\alpha\)-spending functions
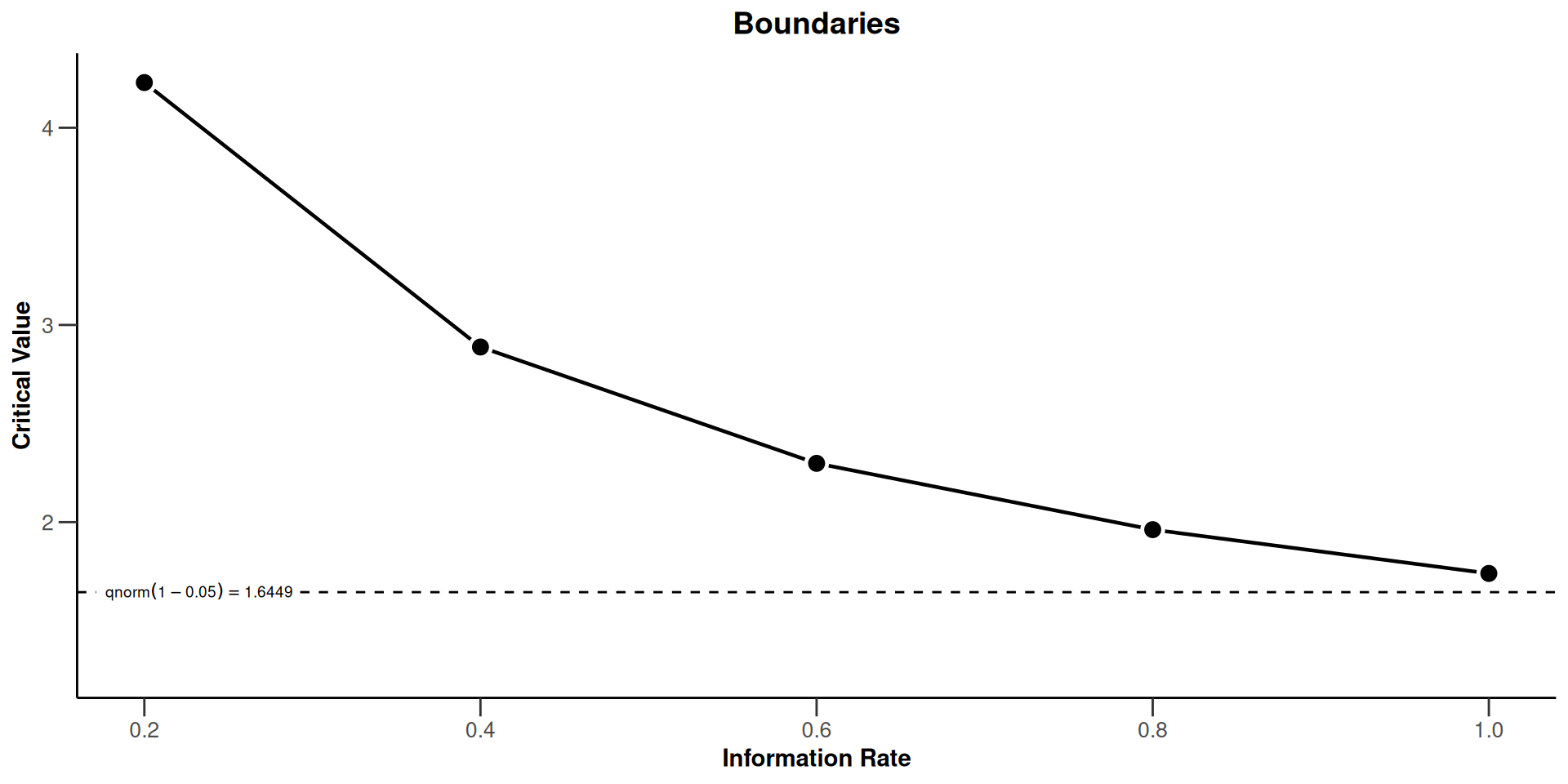
With rpact
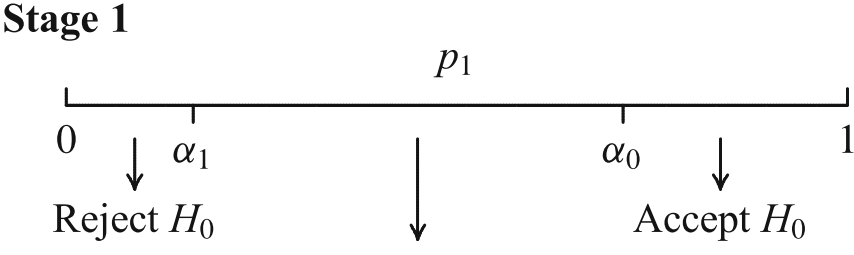
The Combination Test (Bauer ’89, Bauer & Köhne ’94)
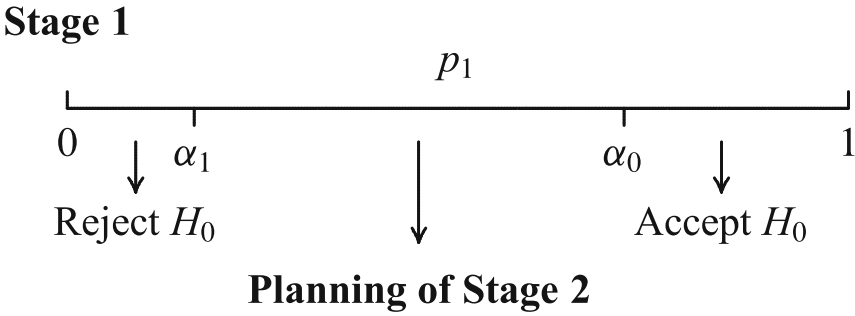
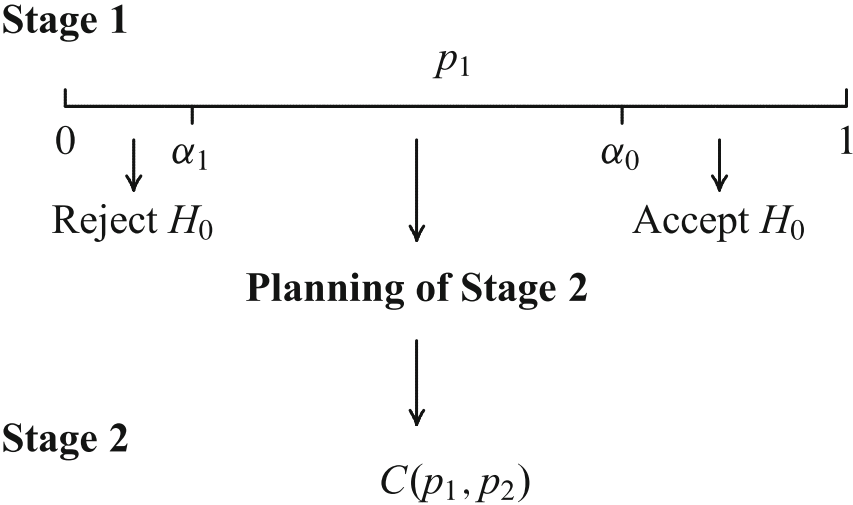
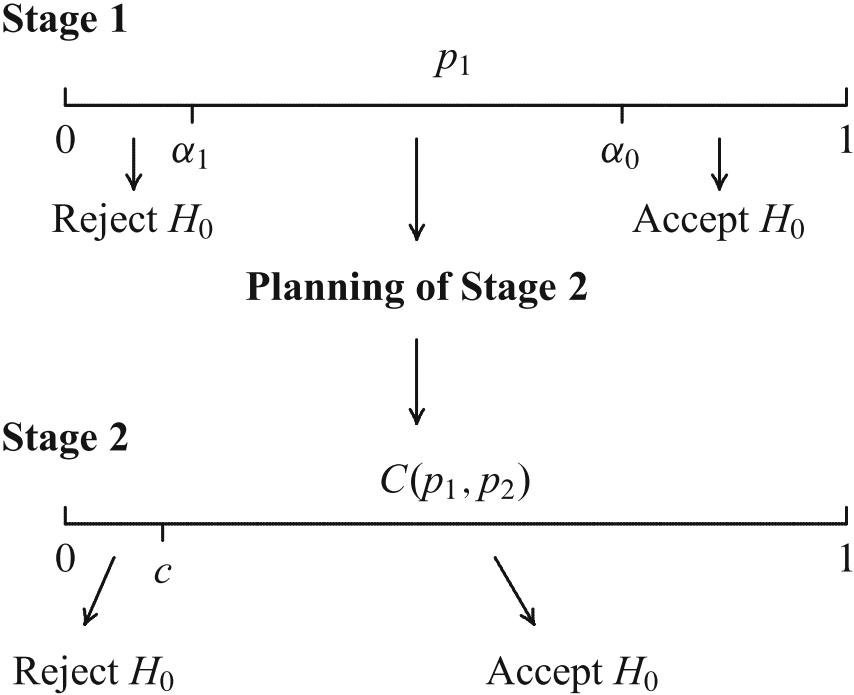
Stopping boundaries and combination function have to be laid down a priori!
Seamless Phase II/III Trials: Treatment Arm Selection
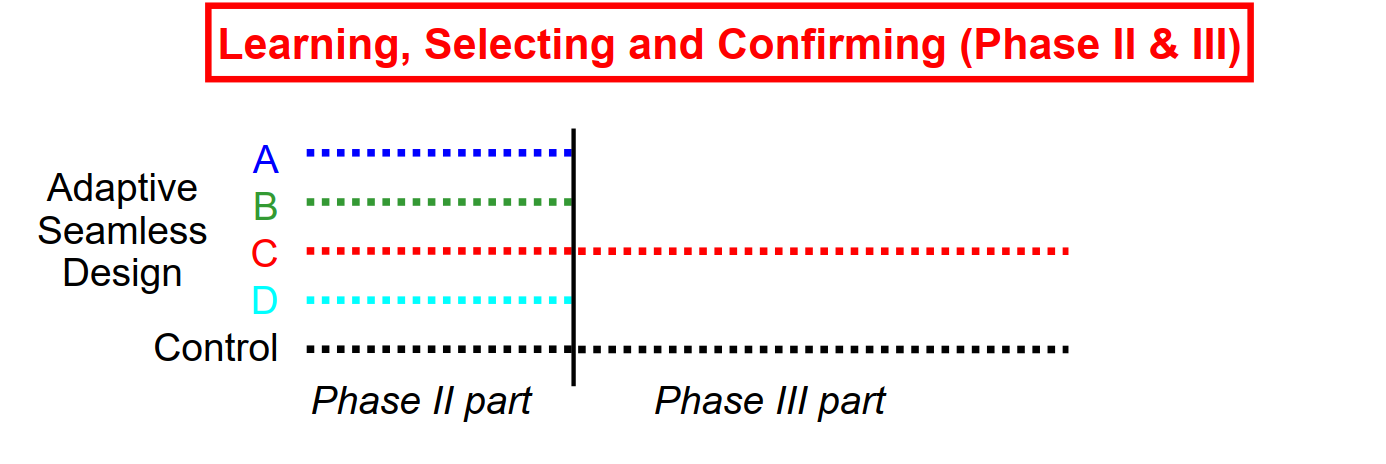
Conduct phase II trial as internal part of a combined trial
Plan phase III trial based on data from phase II part
Conduct phase III trial as internal part of the same trial
Demonstrate efficacy with data from phase II + III part
Enrichment: Phase 2/3 Study in HER2- Early Stage BC
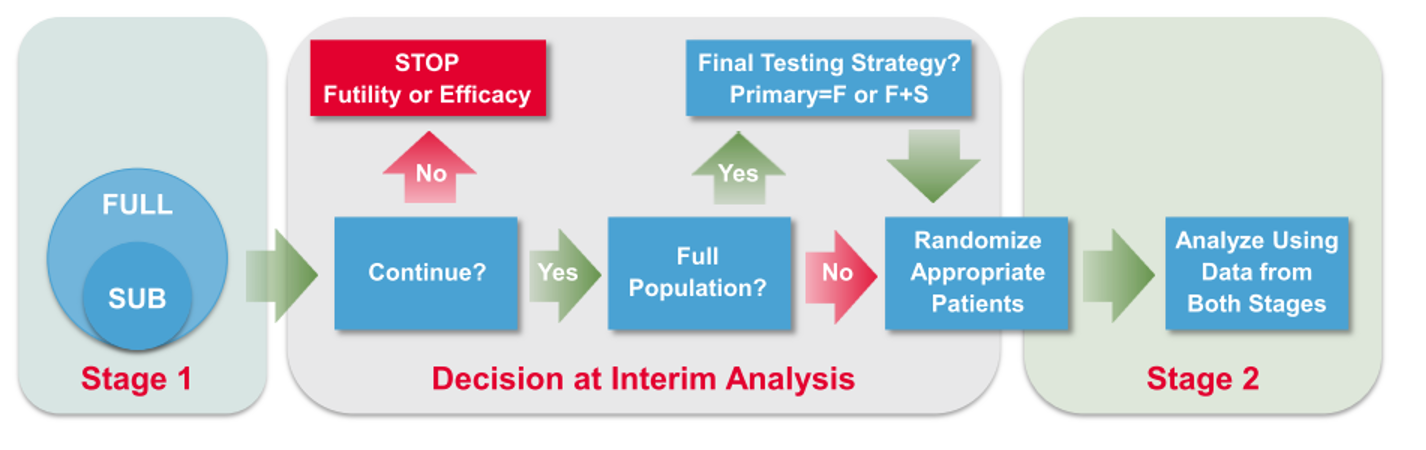
- Stage 1 objective
Stop for futility/efficacy
To continue with HER2- (Full) population – Broad Label (F) or Enhanced Label (F+S)
To confirm greater benefit in TNBC Subpopulation – Restricted Label (S)
To adjust the sample size
- Stage 2 data and the relevant groups from Stage 1 data combined
Two-Stage Closed Testing Principle, 3 Hypotheses, select one
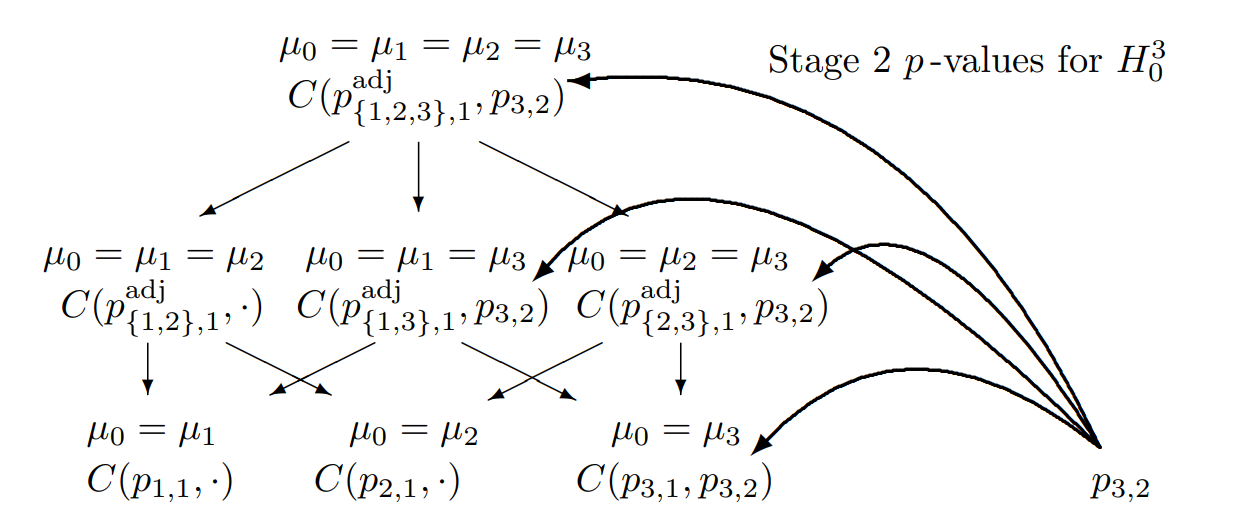
Combination tests to be performed for the closed system of hypotheses (\(G = 3\)) for testing hypothesis \(H_0^3\) if treatment arm 3 is selected for the second stage
Two-Stage Closed Testing Principle, 3 Hypotheses, select two
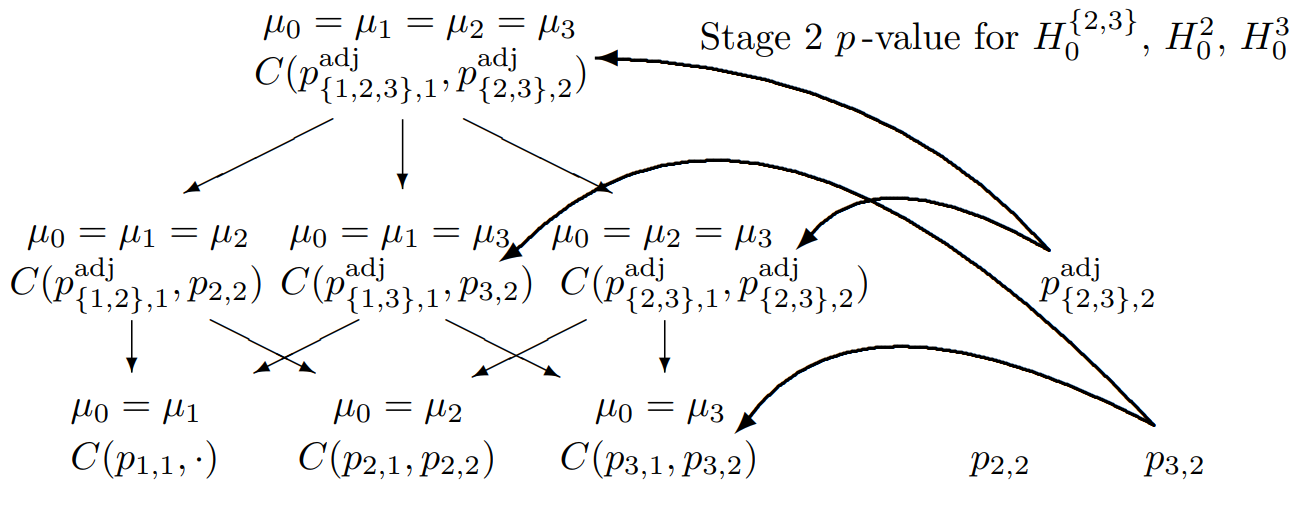
Combination tests to be performed for the closed system of hypotheses (\(G = 3\)) for testing hypothesis \(H_0^3\) if treatment arms 2 and 3 are selected for the second stage